
粒子群算法(Particle Swarm Optimization)是一种启发式优化算法,灵感来源于飞鸟规律性集群活动,进而利用群体智能建立的一个简化模型。粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。粒子群算法相比于其他数学模型实现简单,适用性强,鲁棒性好。
一、背景介绍
粒子群算法是由 J. Kennedy 和 R. C. Eberhart 等于1995年开发的一种演化计算技术,来源于对一个简化社会模型的模拟。随后Shi和Eberhart提出了惯性权重的概念,这应该是一个重要的改进,使得算法能够平衡全局搜索和局部搜索。这让粒子群算法得到了较为广泛的使用空间。
二、基本原理
(1)算法的数学逻辑:
粒子群算法中的粒子并不是物理意义上的粒子,而是生活中随处可见的鸟,在模型中把它描述为没有质量、没有体积的,只需要描述它的速度和加速状态的质点。鸟群往往以一种优美而不可预测的运动行进,而对于鸟群中的每一只鸟,都有他自己的飞行路线和集体最优的飞行路线。
我们假设处于D维的空间里有N只鸟,每只鸟的位置可以表达为一个向量:X_i=(x_{i1},x_{i2},\cdots x_{iD}),i=1,2,\cdots,N,鸟处于不断的运动当中,其每只鸟运动的速度(包括大小方向)表达为另一个向量:V_i= \begin{pmatrix} \nu_{i1},\nu_{i2},\cdots\nu_{iD} \end{pmatrix},i=1,2,\cdots,N ,那么当第t状态向第t+1状态进化时就有如下的表达:x_{ij}(t+1)=x_{ij}(t)+\nu_{ij}(t+1)
而对于{{v}_{ij}}(t)的表达要综合考虑鸟当前的状态、个体最优飞行方案和全局的最优飞行方案。对于鸟当前的状态,我们定义 \mathcal{W}表示鸟的惯性系数,即由于惯性作用,鸟不能立刻改变速度方向。对于鸟个体而言,其清楚自己想去的地方,将这个地方的向量记作{{p}_{ij}}(t),显然它也是随t变化的,鸟在飞行时与同伴交流会了解到整个鸟群想去的地方,记作{{p}_{gj}}(t)。个体会比较当前位置与{{p}_{ij}}(t) 和{{p}_{gj}}(t) 之间距离之差做出抉择,记{{\text{r}}_{i}}(t)为[0,1]之间的某一值,{{\text{c}}_{i}}表示个体的认知常数,即他为权衡个体最优路线与集体最优路线之间做出的选择。综合上面的三个讨论,我们得到{{v}_{ij}}(t\text{+}1)的表达式:
其中 .一般取\mathcal{W}=0.4~0.9,c1,c2一般都设为2。这3个变量值的选取与优化进程有关,一般在优化前期𝜔应该大一些,保证各个粒子独立飞行充分搜索空间,后期应该小一点,多向其他粒子学习。𝑐1,𝑐2分别向个体极值和全局极值最大飞行步长。前期𝑐1应该大一些,后期𝑐2应该大一些,这样就能平衡粒子的全局搜索能力和局部搜索能力。
(2). 模型实施步骤:
输入:参数𝜔:0.4−0.9,𝑐1,𝑐2:0.1−2, {{v}_{\max }},{{\text{x}}_{\max }} :取决于优化函数
Step1:初始化种群𝑥;
Step2:计算个体适应度;
Step3:更新粒子速度−>更新粒子位置;
Step4:并计算新位置的适应度,若新位置适应度更高,则将该粒子的位置进行优化,否则不优化。
Step5:判断是否满足终止条件 ,是则退出,否则返回Step2。
输出:输出最优值。
说明:1.{{v}_{\max }} 表示最大飞行速度,在进行完一轮优化时,计算此时的速度,若判定结果为v\ge {{v}_{\max }},则在下一轮优化前,v应当取{{v}_{\max }} ,同时限定{{\text{x}}_{\max }},即有限时间内粒子不可能飞离某片区域。{{\text{x}}_{\max }}与{{v}_{\max }} 的选取都与待优化函数有关
2.终止条件一般有如下特征(1)人为设定迭代进化次数(2)优化n代时函数值不再变化。
四、应用场景
模拟退火算法的应用领域十分广泛,包括但不限于:
(1)电商平台定价策略优化:通过模拟不同定价方案,找到最大化利润的商品价格。
(2)交通出行路线规划:为个人或共享单车用户找到最优路线,节省时间和距离。
(3)空气质量监控网络部署:优化传感器布局,确保全面覆盖,提高环境监测效果。
五、实证分析
求函数x^2+y^2+z^2+10\cdot\sin(x)+10\cdot\sin(y)+10\cdot\sin(z)的最小值,其中x,y,z\in [-10,10]。
(1)确定参数的选择。初始化粒子群体总数N=500,粒子维数D=3,学习因子c1=c2=2,惯性权重 为0.8,考虑x,y,z的范围,选取{{\text{x}}_{\max }}=10,{{\text{x}}_{\min }}=-10,速度最大值{{v}_{\max }}选取为0.5,最小速度{{v}_{\min }}为-0.5,最大迭代次数为20次。
(2)优化的思路。更新粒子的位置和速度等信息,不断计算此时的适应度,知道达到最大迭代的20次,记录下此时的适应度。
上述求解步骤的MATLAB代码如下:
N = 500; % 粒子数目
D = 3; % 变量维数 (x, y, z)
T = 20; % 最大迭代次数
c1 = 2; % 个体学习因子
c2 = 2; % 全局学习因子
w = 0.8; % 惯性权重
Xmax = 10; % 位置上界
Xmin = -10; % 位置下界
Vmax = 0.5; % 速度上界
Vmin = -0.5; % 速度下界
function result = func1(x)
result = sum(x.^2) + 10 * sum(sin(x));
end
% 初始化粒子的位置和速度
x = rand(N, D) * (Xmax - Xmin) + Xmin;
v = rand(N, D) * (Vmax - Vmin) + Vmin;
p = x; % 每个粒子的个体最佳位置初始化为当前位置
pbest = zeros(N, 1);
for i = 1:N
pbest(i) = func1(x(i, :));
end
% 初始化全局最优位置及其适应度
g = p(1, :);
gbest = pbest(1);
for i = 1:N
if pbest(i) < gbest
g = p(i, :);
gbest = pbest(i);
end
end
gb = zeros(T, 1);
for t = 1:T
for j = 1:N
current_val = func1(x(j, :)); % 计算当前粒子适应值
if current_val < pbest(j)
p(j, :) = x(j, :);
pbest(j) = current_val;
end
if pbest(j) < gbest% 更新全局最佳位置及适应值
g = p(j, :);
gbest = pbest(j);
end
v(j, :) = w * v(j, :) ...
+ c1 * rand(1, D) .* (p(j, :) - x(j, :)) ...
+ c2 * rand(1, D) .* (g - x(j, :));
x(j, :) = x(j, :) + v(j, :);
for ii = 1:D% 边界条件处理
if (v(j, ii) > Vmax || v(j, ii) < Vmin)
v(j, ii) = rand * (Vmax - Vmin) + Vmin;
end
if (x(j, ii) > Xmax || x(j, ii) < Xmin)
x(j, ii) = rand * (Xmax - Xmin) + Xmin;
end
end
end
gb(t) = gbest;
fprintf('第 %d 次迭代,全局最佳适应值:%f\n', t, gbest);
end
disp('最优位置:');
disp(g);
disp('最优函数值:');
disp(gbest);
figure;
plot(gb, 'LineWidth', 2);
xlabel('迭代次数');
ylabel('最优适应值');
title('适应值迭代曲线');最后得到的优化曲线如图所示:
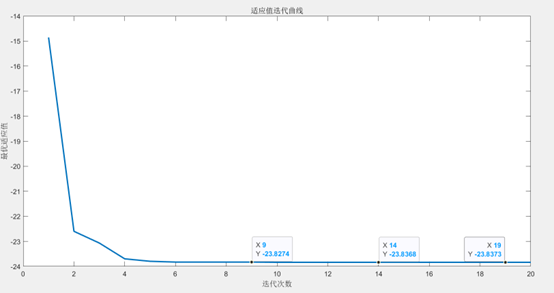
由图中发现,当迭代次数达到8次左右适应度已经几乎不变,随着迭代次数的进一步升高,其值集中在-23.837左右。迭代次数较少就得到了最优的结果,这可能与我们选取的粒子总数500个比较多有关。
六、方法评价
(1)优点:
简单易实现:PSO算法的思想简单直观,实现起来相对容易,只需要少量的参数(如惯性权重、学习因子等)即可运行;
计算效率高:PSO收敛速度较快,尤其适合解决中小规模优化问题,每次迭代只需计算目标函数值和更新粒子的位置和速度;
(2)缺点:
容易陷入局部最优:在某些情况下,粒子可能会过早收敛到局部最优,而不是全局最优,特别是在高维或复杂多模函数中,性能可能不佳;
参数敏感性:算法的性能对惯性权重(ω)、个体学习因子(c1)和全局学习因子(c2)高度依赖,参数选择不当可能导致算法收敛过慢甚至发散;
粒子多样性不足:在某些情况下,粒子的位置和速度可能会迅速趋同,导致多样性丧失,从而影响全局搜索能力。
七、拓展阅读
粒子群算法中的权重并不是完全不变的,我们可以进一步探讨如何通过引入惯性权重调整、多样性维持策略等方法来避免陷入局部最优。例如Clerc提出的压缩因子粒子群算法。尽管PSO主要依赖实验验证,但有一些研究致力于从数学角度探讨其收敛性和搜索能力。这包括对粒子轨迹的分析以及群体行为的建模,有助于更好地理解算法的内在机制。同时在粒子群算法与模拟退火算法可以说是优缺点互补的,因此我们可以在PSO中加入一定概率接受劣解,以增加算法的多样性,通过模拟退火的温度调节策略,动态调整学习因子或惯性权重,从而提高PSO避免陷入局部最优的能力,增强全局搜索能力。

