
GPT-SoVITS-WebUI是一个强大的少样本语音转换与语音合成Web用户界面.
零样本文本到语音 (TTS): 输入 5 秒的声音样本, 即刻体验文本到语音转换.
少样本 TTS: 仅需 1 分钟的训练数据即可微调模型, 提升声音相似度和真实感.
跨语言支持: 支持与训练数据集不同语言的推理, 目前支持英语、日语、韩语、粤语和中文.
WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注, 协助初学者创建训练数据集和 GPT/SoVITS 模型.
原项目地址展示的示例:
安装 Anaconda/Miniconda
GPT-SoVITS 项目推荐使用 conda 环境进行管理。如果尚未安装 Anaconda 或 Miniconda,请先安装.
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 激活 conda 环境
source ~/.bashrc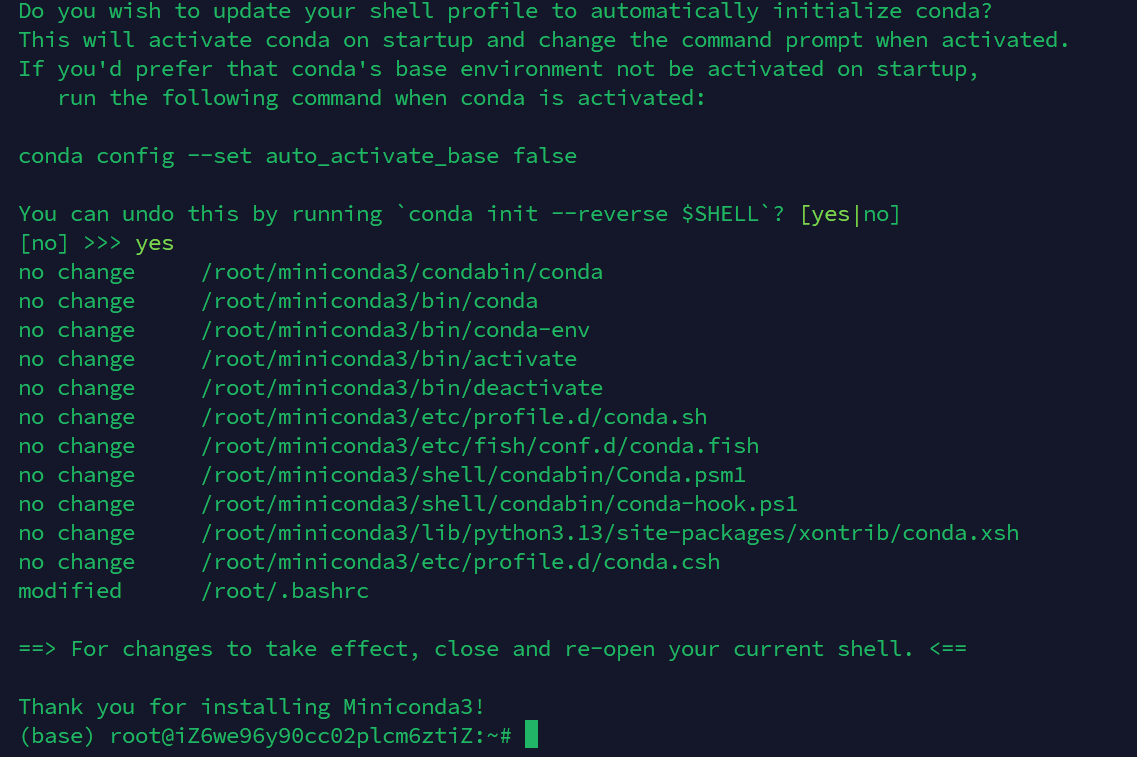
创建并激活 Conda 环境
conda create -n GPTSoVits python=3.10
conda activate GPTSoVits安装系统依赖:
项目文档中提到了 ffmpeg 和 libsox-dev,这些是 Ubuntu 系统上的依赖。如果没有预先安装,需要执行下列命令:
sudo apt update
sudo apt install ffmpeg -y
sudo apt install libsox-dev -y
依赖的安装依据服务器性能,大约需要2分钟左右。
克隆项目仓库:
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS检测服务器CPU性能和CUDA版本:
由于该项目支持使用GPU进行加速推理和演化,因此有必要实现确定本服务器是否具备此功能,要确认Ubuntu 服务器是否支持 CUDA,主要检查以下两个方面:
1.NVIDIA GPU 硬件是否存在且正常工作。
2.NVIDIA 驱动程序是否已正确安装。
检查 NVIDIA GPU 硬件
首先,我们需要确认服务器是否安装了 NVIDIA 显卡。您可以使用 lspci 命令来列出所有 PCI 设备,并过滤出与 NVIDIA 相关的设备。
lspci | grep -i nvidia如果服务器安装了 NVIDIA 显卡,可能会看到类似以下的输出:
01:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)
01:00.1 Audio device: NVIDIA Corporation GP102 HDMI Audio Controller (rev a1)如果没有任何输出,或者输出中没有包含“NVIDIA”字样,那么您的服务器可能没有安装 NVIDIA 显卡,或者显卡没有被系统识别。在这种情况下,您的服务器将无法支持 CUDA。那么可以不需要进行下一步检测,直接选择使用CPU进行计算,缺失了加速推理和计算的过程.
2.检查 NVIDIA 驱动程序
如果服务器安装了 NVIDIA 显卡,下一步是检查 NVIDIA 驱动程序是否已正确安装并加载。可以使用 nvidia-smi 命令来查看 NVIDIA GPU 的状态和驱动程序信息。nvidia-smi 是 NVIDIA System Management Interface 的缩写,它是一个命令行实用程序,用于监控和管理 NVIDIA GPU 设备。
nvidia-smi如果 NVIDIA 驱动程序已正确安装,可以看到类似以下的输出,其中包含驱动版本、CUDA 版本、GPU 温度、内存使用情况等信息:
Fri Jun 20 03:45:00 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MEX |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| N/A 38C P8 12W / 250W | 0MiB / 11264MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+检查 CUDA Toolkit 安装情况
nvidia-smi 命令的输出中会显示 CUDA Version,这表示驱动程序支持的最高 CUDA 版本。但这并不意味着 CUDA Toolkit 已经安装。CUDA Toolkit 是一个开发环境,包含了编译器、库和工具,用于在 NVIDIA GPU 上进行并行计算。
要检查 CUDA Toolkit 是否安装,以及其版本,可以尝试查找 nvcc 编译器。nvcc 是 CUDA C++ 编译器。
which nvcc nvcc --version如果 CUDA Toolkit 已安装,可能会看到类似以下的输出:
/usr/local/cuda/bin/nvcc nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Tue_Aug_15_22:02:13_PDT_2023 Cuda compilation tools, release 12.2, V12.2.140 Build cuda_12.2.r535.104-cf28d39a如果 which nvcc 没有输出,或者 nvcc --version 报错,则表示 CUDA Toolkit 没有安装或者没有正确配置环境变量。在这种情况下,则需要根据您的 Ubuntu 版本和 NVIDIA 驱动版本安装 CUDA Toolkit。可以访问 NVIDIA 官方 CUDA Toolkit 下载页面获取详细的安装指南。
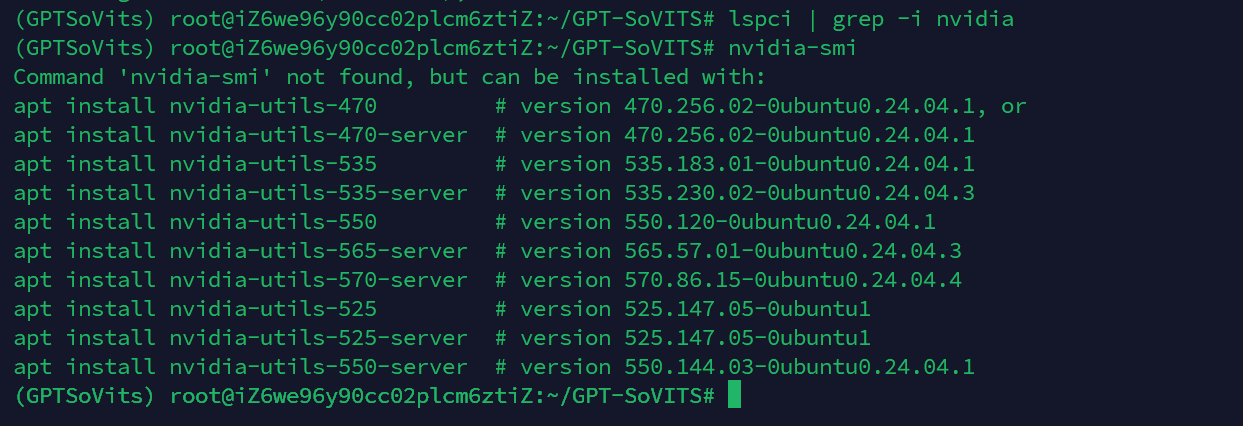
出现以上信息则代表该服务器不具备GPU推理加速,只能使用CPU计算。
运行安装脚本
项目提供了一个 install.sh 脚本来简化安装过程。您需要根据您的设备类型选择 --device 参数,并选择 --source 参数。
•--device:
•CU126: 适用于 CUDA 12.6
•CU128: 适用于 CUDA 12.8
•ROCM: 适用于 ROCm
•CPU: 适用于 CPU
•--source:
•HF: 从 Hugging Face 下载模型
•HF-Mirror: 从 Hugging Face 镜像下载模型
•ModelScope: 从 ModelScope 下载模型
应当根据实际情况选择合适的参数。 例如,如果服务器支持 CUDA 12.8,并且希望从 Hugging Face 下载模型,命令如下:
bash install.sh --device CU128 --source HF如果需要下载 UVR5 模型(人声/伴奏分离),可以添加 --download-uvr5 参数:
bash install.sh --device CU128 --source HF --download-uvr5由于本服务器不具备GPU推理的功能,因此采用CPU-HF的架构部署:
注意此过程需要下载大量文件,因此需要消耗大量时间,大约30mins(保持20MB/s左右的下载速度实测)
TIPS:
本人在实测时遇到了如下报错:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/root/miniconda3/envs/GPTSoVits/lib/python3.10/site-packages/pyopenjtalk/__init__.py", line 26, in <module>
from .openjtalk import OpenJTalk
ImportError: /root/miniconda3/envs/GPTSoVits/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.32' not found (required by /root/miniconda3/envs/GPTSoVits/lib/python3.10/site-packages/pyopenjtalk/openjtalk.cpython-310-x86_64-linux-gnu.so)
[ERROR]: Command "PYOPENJTALK_PREFIX=$(python -c "import os, pyopenjtalk; print(os.path.dirname(pyopenjtalk.__file__))")" Failed at Line 341 with Exit Code 1
[ERROR]: Call Stack:
in main() at install.sh:341这可能是因为 Conda 环境中的库版本与系统库版本存在冲突Conda 环境中的 pyopenjtalk 模块对 libstdc++ 的特定版本有严格要求,并且没有正确链接到系统或 Conda 中更新的库。
因此我们在 Conda 环境中安装 libstdcxx-ng,它通常能提供更兼容的 C++ 标准库版本。请您运行以下命令:
conda install -c conda-forge libstdcxx-ng -y随后继续执行以下命令,重新安装:
bash install.sh --device CPU --source HF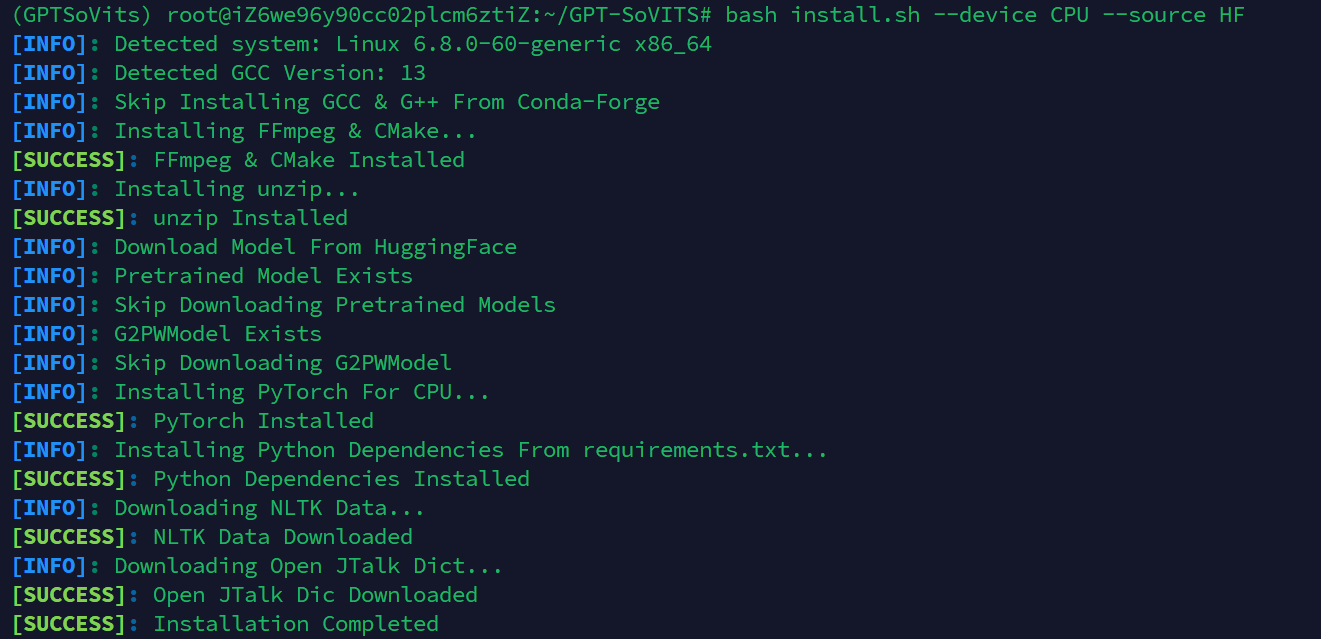
出现了如上的提示代表python和C/C++的依赖全部安装成功。
模型的安装
首先安装Git LFS,其可以用来用于处理大型文件
sudo apt update
sudo apt install git-lfs -y安装完成后,运行以下命令将GPT-SoVITS 的预训练模型应该已经通过 Git LFS 下载到您的 GPT_SoVITS/pretrained_models 目录中:
git lfs install
git pullUVR5 Weights (人声/伴奏分离和混响移除,额外功能)
mkdir -p tools/uvr5/uvr5_weights
wget -O tools/uvr5/uvr5_weights/HP_filter.pth https://huggingface.co/RVC-Boss/GPT-SoVITS/resolve/main/tools/uvr5/uvr5_weights/HP_filter.pth
# 您需要对该页面下的所有 .pth 文件重复此操作
中文 ASR (额外功能 )
mkdir -p tools/asr/models
wget "https://www.modelscope.cn/api/v1/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online/repo?Revision=master&FilePath=model.pt" -O tools/asr/models/Damo_ASR_model.pt
wget "https://www.modelscope.cn/api/v1/models/damo/speech_fsmn_vad_zh-cn-16k-common-trie-3/repo?Revision=master&FilePath=model.pt" -O tools/asr/models/Damo_VAD_model.pt
wget "https://www.modelscope.cn/api/v1/models/damo/punc_ct-transformer_cn-en-common-vocab471067-large/repo?Revision=master&FilePath=model.pt" -O tools/asr/models/Damo_Punc_model.pt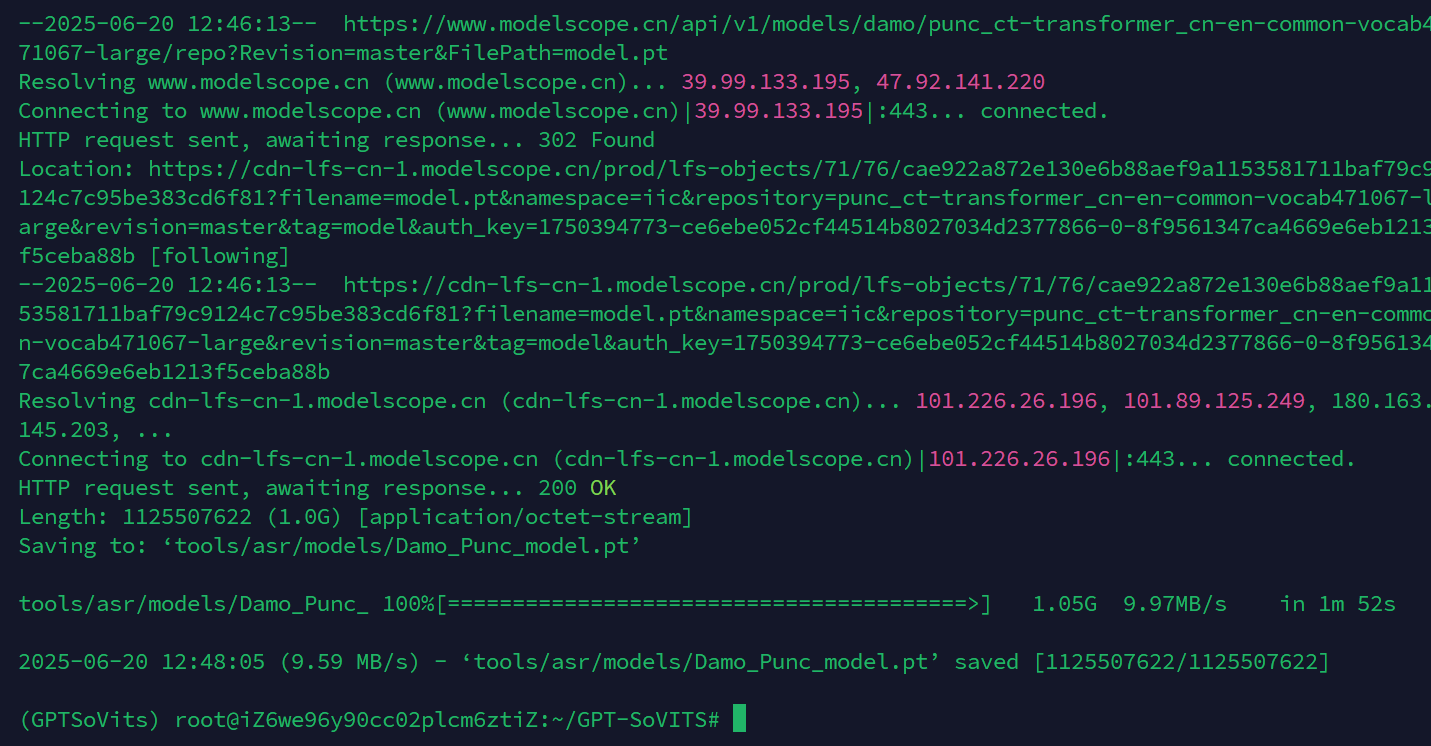
此包大约需要1.05G,安装完成后的提示如上图所示。
英语日语ASR模型下载
mkdir -p tools/asr/models/FasterWhisper-large-v3
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=config.json" -O tools/asr/models/FasterWhisper-large-v3/config.json
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=configuration.json" -O tools/asr/models/FasterWhisper-large-v3/configuration.json
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=model.bin" -O tools/asr/models/FasterWhisper-large-v3/model.bin
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=preprocessor_config.json" -O tools/asr/models/FasterWhisper-large-v3/preprocessor_config.json
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=README.md" -O tools/asr/models/FasterWhisper-large-v3/README.md
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=tokenizer.json" -O tools/asr/models/FasterWhisper-large-v3/tokenizer.json
wget -c "https://www.modelscope.cn/api/v1/models/keepitsimple/faster-whisper-large-v3/repo?Revision=master&FilePath=vocabulary.json" -O tools/asr/models/FasterWhisper-large-v3/vocabulary.json
此包大约需要2.88G,安装完成后的提示如下图所示。
启动WEBUI程序:
在 ~/GPT-SoVITS/ 目录下运行以下命令:
python webui.py想直接启动推理 WebUI,可以运行:
python GPT_SoVITS/inference_webui.py
